AI 视频生成的原理与核心技术突破
AI 视频生成是利用扩散模型(Diffusion Models)和变换器架构(Transformers)将文本、图像或视频片段转化为动态视觉内容的计算过程。截至 2026 年 3 月,该技术已由简单的短片生成演变为具备物理规律模拟和长时长连贯性的工业工具,在电影预演、广告投放和社交短视频领域实现了商业闭环。
当前模型的核心突破在于时空潜空间(Spatiotemporal Latent Space)的优化。
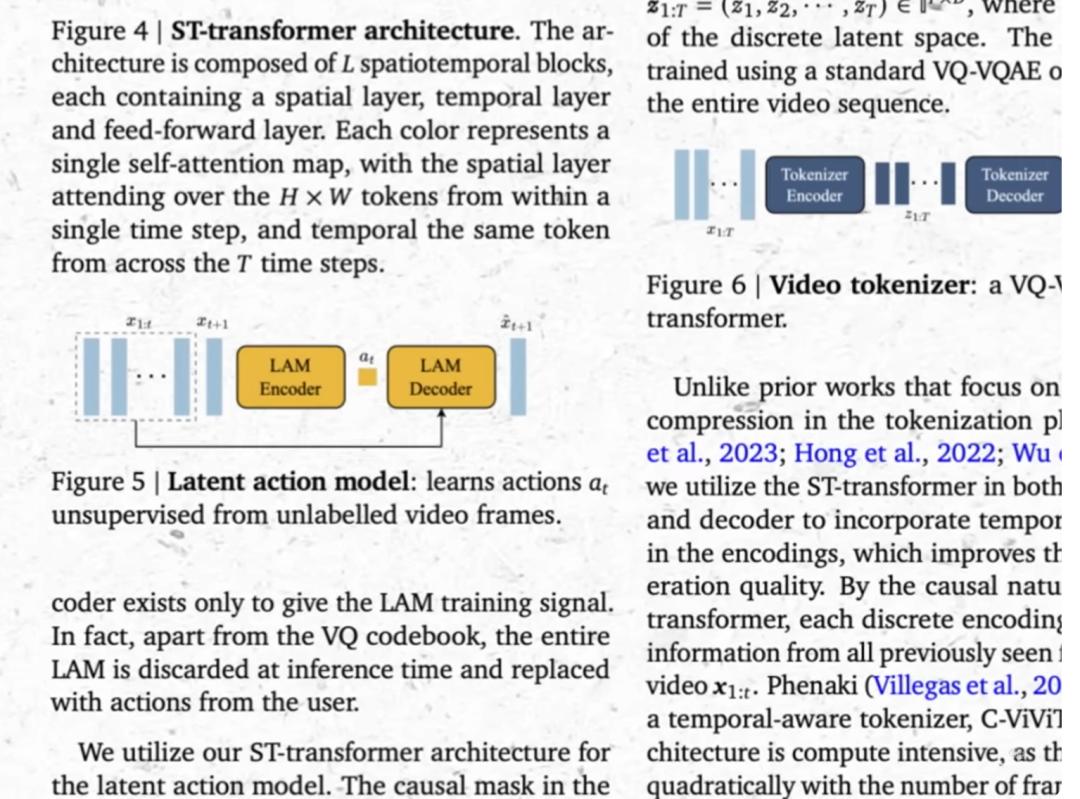
早期模型因缺乏时间轴约束,常出现物体消失或形变;而 Sora 2 或 Kling 2.6 等当代模型采用 3D 注意力机制,将视频视为时空补丁(Patches),使其在生成后续帧时能维持第一帧的角色细节与光影方向,从而模拟出接近现实世界的物理引擎。
主流 AI 视频工具的职能分化与选择
市面上的工具呈现明显的职能分化,用户应根据视觉目标选择对应的模型。
| 工具名称 | 核心优势 | 适用场景 |
|---|---|---|
| Sora 2 / Kling 2.6 | 复杂光影、流体动力学、电影感 | 高视觉冲击力短片、广告大片 |
| Seed Edit | 局部精准控制、分层编辑 | 角色特定动作修改、精准后期调整 |
| Wan 2.6 | 图像忠实度、多模态引导 | 图生视频(I2V)高一致性创作 |
在专业生产链路中,能够精准修改的工具比仅能生成 10 秒惊艳片段的模型效率更高。
工业级视频产出的三步实操工作流
高质量作品的产出依赖于工程化流程,而非随机的 Prompt 抽卡。
第一步:构建结构化时空描述词

示例: 主体为身穿深灰色羊绒大衣、面容憔悴的 40 岁男性;动作是缓慢行走在霓虹灯闪烁的东京街头,雨水在衣领处积聚并滴落;镜头采用 35mm 焦段低角度跟拍,伴随轻微手持晃动;光影为冷色调,路面有积水反射;物理动态要求雨滴碰撞地面产生微小水花。
若画面出现腿部重叠等形变,可将“运动幅度(Motion Bucket/Strength)”调至 3-5,并增加负向提示词。
Negative Prompt: morphing, distorted limbs, floating objects, blurry face, flickering lighting第二步:执行多模态引导生成

纯文本生成(T2V)随机性过强,建议采用“图生视频(I2V)”或“视频生视频(V2V)”以确定构图与角色。
第三步:时空一致性修补与后期升频
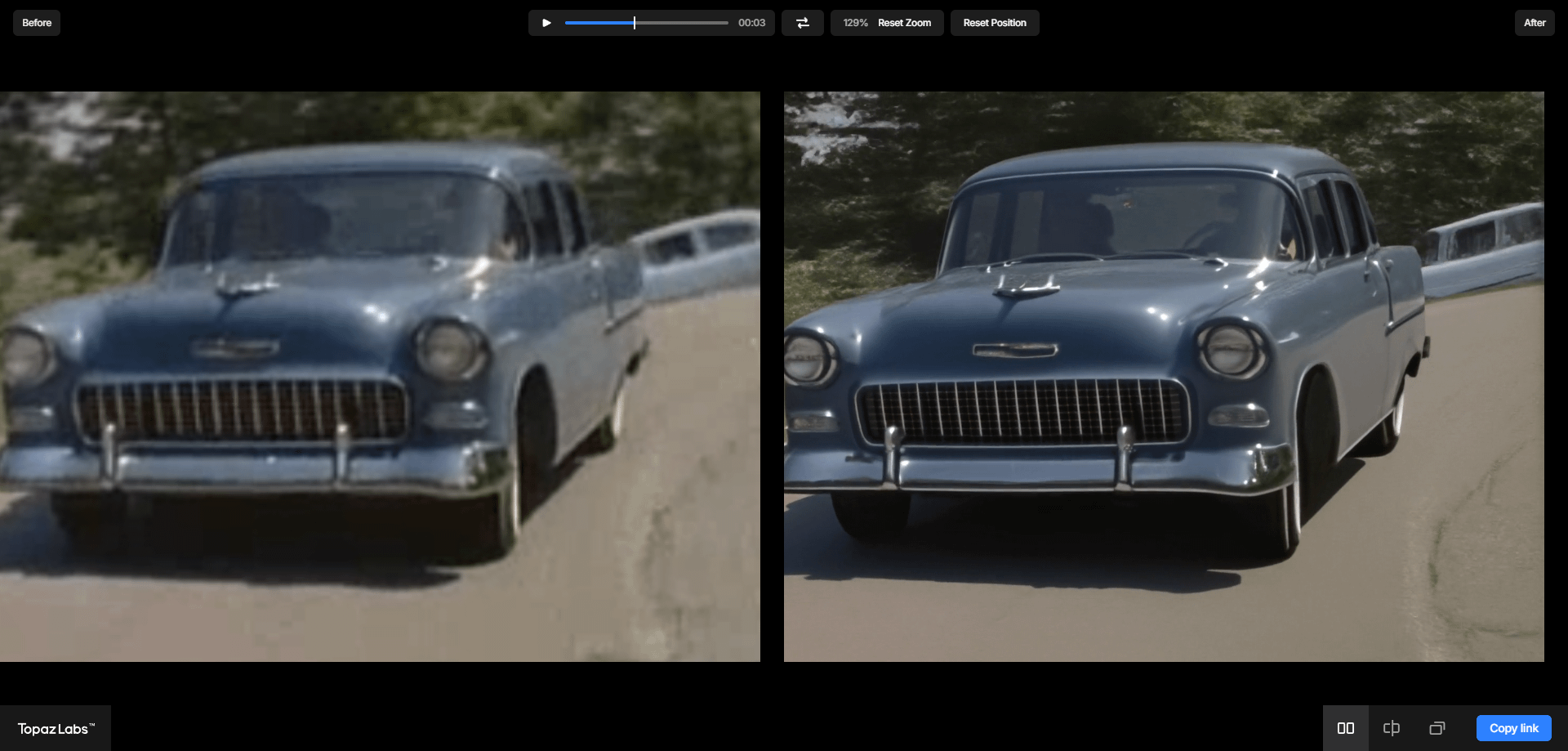
针对局部闪烁,可使用 Seed Edit 选取帧区间,通过掩码(Mask)重绘确保像素平滑。
商业化落地的成本、版权与局限性
AI 视频生成在带来效率提升的同时,也伴随显著的成本与法律风险。
成本陷阱: 初学者易低估订阅与计算成本。随着画质要求提升,因频繁重绘和渲染,单月预算可能从 200 美元攀升至 600 美元。
版权归属: 法律界定仍存在模糊地带。部分模型提供方可能保留部分权利,导致作品在进入国际电影节或商业版权交易时易陷入权属纠纷。
哪些场景不建议强行使用 AI 视频?
1. 极致细节特写(如皮肤毛孔动态),AI 易用平滑滤镜覆盖纹理;
2. 严密逻辑的复杂动作(如解开绳结),易出现空间穿模;
3. 超长时长单一场景叙事,目前算力难以维持长时间的角色视觉零漂移。
目前最高效的生产方式是什么?
构建能容纳多个工具的组合工作流,将 I2V(图生视频)作为核心路径,通过控制静态图来掌控动态视频。