从像素模拟到物理拟合:AI 视频的工业化进程
AI 视频生成正从单纯的像素模拟进化为对物理规律的拟合。截至 2026 年 3 月,该技术已走出 Demo 阶段,在广告、短视频和独立电影领域产生实际经济价值。但随着应用规模扩大,版权归属与算力成本正成为专业团队部署的核心阻碍。
目前 AI 视频正处于从单一模型向工作流(Workflow)转变的拐点。专业用户已不再依赖随机的提示词抽奖,而是利用 Sora 2、Kling 2.6 或 Wan 2.6 实现分镜控制、角色一致性维持及局部重绘。AI 的角色已从替代导演的工具,转变为一个高效且高成本的数字摄影棚。
技术底层方面,顶尖模型基本遵循 DiT(Diffusion Transformer)架构,将视频视为时空补丁(Spatiotemporal Patches)。模型在潜在空间中对补丁进行噪声处理,并根据指令预测像素在时间维度上的演变。由于学习到了更高维度的物理表征,2025 年后的模型在处理水流、烟雾等流体动力学时,视觉效果比早期版本更自然。
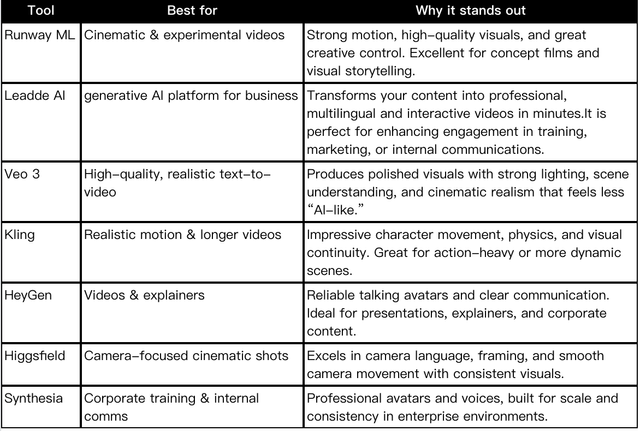
主流 AI 视频工具能力分层与成本分析
当前市场工具的分层趋势明显,不同模型在长镜头稳定性与场景构建能力上各有侧重。
| 模型名称 | 核心优势 | 适用场景 | 局限性 |
|---|---|---|---|
| Kling 2.6 | 人体动作自然、长镜头稳定性强 | 人物驱动短片、长镜头叙事 | 算力成本较高 |
| Sora 2 | 宏大场景构建、光影一致性极佳 | 概念片、视觉奇观 | 生成时间较长 |
| HAILUO / Seed Edit | 低延迟实时生成、局部快速修改 | 快速迭代、素材填充 | 复杂物理拟合稍逊 |
然而,高质量生成的算力费用(Credit)极高。在部分复杂项目中,AI 迭代的成本甚至超过了实拍人力成本,这使得 AI 视频的经济效益在不同项目规模下呈现出不稳定性。
实操指南:构建「分步控制工作流」
对于落地项目,建议采用「分步控制工作流」替代纯 Prompt 生成,以确保商业级的可控性。
先用 Midjourney 或 Stable Diffusion 生成 3-5 张多角度角色参考图,通过 Image-to-Video 功能输入。将「创意度/随机性」调至 0.3,将「一致性」权重提升至 0.8,以降低角色在 10 秒内变脸的概率。若肢体畸变,可尝试降低 FPS 或使用 Seed Edit 进行局部遮罩重绘,锁定角色轮廓。
使用运动笔刷或轨迹线定义位移,将「运动强度」设在 4-6 之间。强度过高易导致画面撕裂,过低则缺乏动态感。若出现拉伸变形,可在负面提示词中加入 "warping, stretching, morphing" 进行修正。

针对原片分辨率不足和闪烁问题,将视频切分为 2 秒片段,使用 4K 升采样模型并开启「时间轴平滑」。去噪强度控制在 0.2 左右,以保留细节纹理。严重闪烁可用光学流法(Optical Flow)补帧,将 720P 片段提升至商业级 4K 画质。

AI 视频生成的局限性与现实挑战
尽管效率提升,但版权确权依然是商业应用中最核心的痛点。例如谷歌 Veo3 的版权条款在专业领域争议较大,若训练数据未经授权或法律不认定 AI 作品为「原创」,商业合同中将面临极大法律风险。
此外,AI 视频在两类场景中表现欠佳:
- 高精度产品展示: AI 随机性会导致产品细节(如螺丝钉位置)在镜头推移中发生微小变形,这种「AI 幻觉」在商业广告中是致命的。
- 深层情感特写: AI 难以模拟人类演员带有潜台词的眼神流转,处理「灵魂细节」时依然僵硬。

Q:面对快速迭代的模型,创作者应该如何应对?
与其追求掌握每一个新工具,不如构建自己的「资产库」。将 AI 素材视为原片,通过剪辑、调色和音效设计赋予生命力。AI 解决的是产生影像的问题,而导演解决的是如何讲故事的问题。
Q:初学者应该从哪里开始实践?
<建议从 15 秒短片起步,重点测试 Image-to-Video 的一致性,而非沉溺于文本生成的随机惊喜。